
基于Neo4j的电影数据可视化
本文主要内容为:
- 基于requests + BeautifulSoup抓取时光网电影数据;
- 基于电影数据构建电影和关系实体信息;
- 数据导入neo4j进行存储分析;
- 基于Bottle框架的对neo4j数据进行查询可视化展示。
效果展示: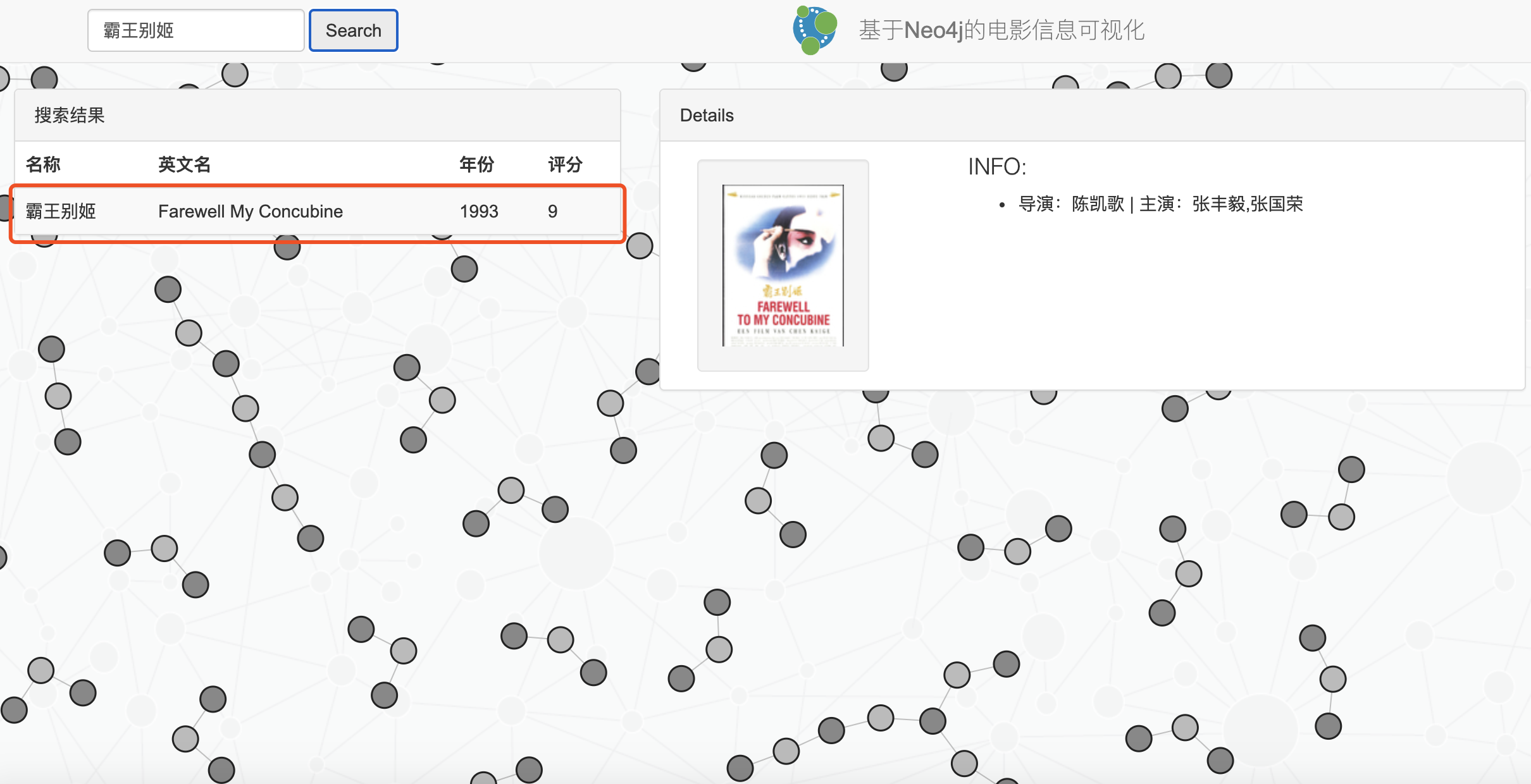
环境配置
新建虚拟环境并安装所需包
- 新建虚拟环境:
1
2
3
4
5
6
7
8# 查看本机已经安装的python虚拟环境
conda env list
# 新建graph-37环境
conda create -n graph-37 python=3.7
# 生效新建的虚拟环境
conda activate graph-37
## 退出
#conda deactivate - 安装所需包:
根据requirements.txt文件来安装:requirements.txt文件:1
pip install -r requirements.txt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25beautifulsoup4==4.9.1
bs4==0.0.1
certifi==2020.4.5.1
chardet==3.0.4
Click==7.0
colorama==0.4.3
et-xmlfile==1.0.1
idna==2.9
jdcal==1.4.1
lxml==4.5.1
neobolt==1.7.17
neotime==1.7.4
numpy==1.18.5
openpyxl==3.0.3
pandas==1.0.4
prompt-toolkit==2.0.10
py2neo==4.3.0
Pygments==2.3.1
python-dateutil==2.8.1
pytz==2020.1
requests==2.23.0
six==1.15.0
soupsieve==2.0.1
urllib3==1.24.3
wcwidth==0.2.4
数据获取
本文数据来自时光网电影Top100。
基于python对该源进行数据抓取,并将数据生成相应的实体和关系:
可参考:GitHub:时光网数据抓取处理
实体和关系如下::
电影:
1
2
3
4index:ID,rank,src,name,movie_en,year,image,:LABEL
10000,1,http://movie.mtime.com/12231/,肖申克的救赎,The Shawshank Redemption,1994,http://img31.mtime.cn/mt/2014/03/07/123549.37376649_96X128.jpg,电影表
10001,2,http://movie.mtime.com/99547/,盗梦空间,Inception,2010,http://img31.mtime.cn/mt/2014/01/06/105446.89493583_96X128.jpg,电影表
...演员:
1
2
3
4
5
6index:ID,actor,:LABEL
30000,杰伊·巴鲁切尔,演员表
30001,维果·莫腾森,演员表
30002,布拉德·皮特,演员表
30003,李·科布,演员表
...导演:
1
2
3
4
5
6index:ID,director,:LABEL
20000,彼得·索恩,导演表
20001,克里斯托弗·诺兰,导演表
20002,朴赞郁,导演表
20003,赛尔乔·莱昂内,导演表
...
关系:
电影与导演关系:
1
2
3
4
5:START_ID,:END_ID,relation,:TYPE
20069,10000,导演,导演
20001,10001,导演,导演
20010,10002,导演,导演
...电影与主演关系:
1
2
3
4
5
6:START_ID,:END_ID,relation,:TYPE
30156,10000,主演,主演
30026,10000,主演,主演
30063,10001,主演,主演
30031,10001,主演,主演
...导演和演员关系:
1
2
3
4
5:START_ID,:END_ID,relation,:TYPE
20069,30156,相关,相关
20069,30026,相关,相关
20001,30063,相关,相关
...
Neo4j存储
数据导入
必须停止neo4j;只能生成新的数据库,而不能在已存在的数据库中插入数据。
通过下面的命令导入定义好的实体和关系数据:
1 | #!/bin/sh |
数据查看
修改配置将默认db改为刚才新建的电影的db,否则还是默认的库。
vim conf/neo4j.conf
1 | dbms.active_database=MovieMTime.db |
启动neo4j服务(neo4j版本为4.0.3):
1 | ./bin/neo4j start |
进入管理界面:http://127.0.0.1:7474
查看实体数据: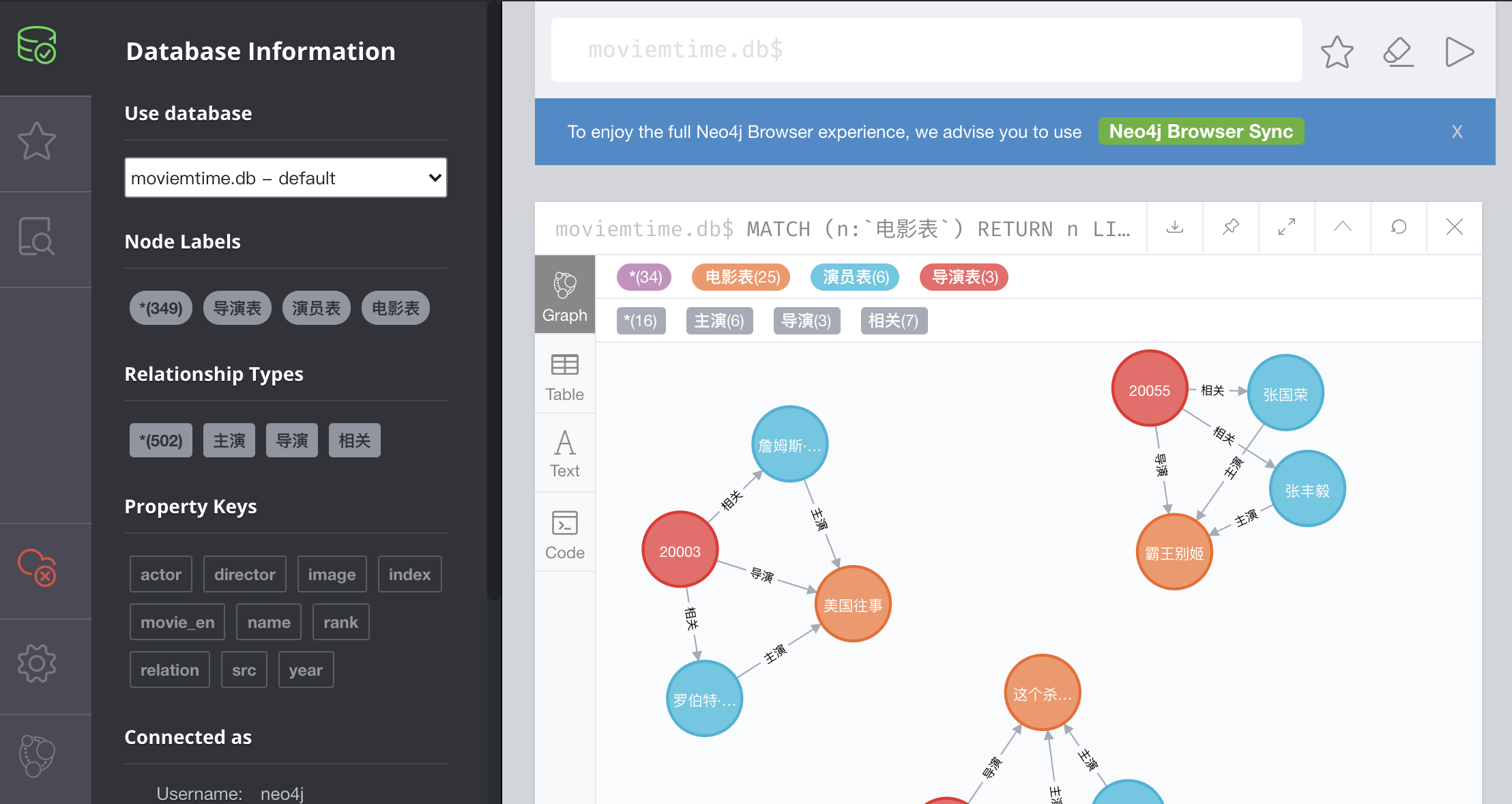
查看关系数据: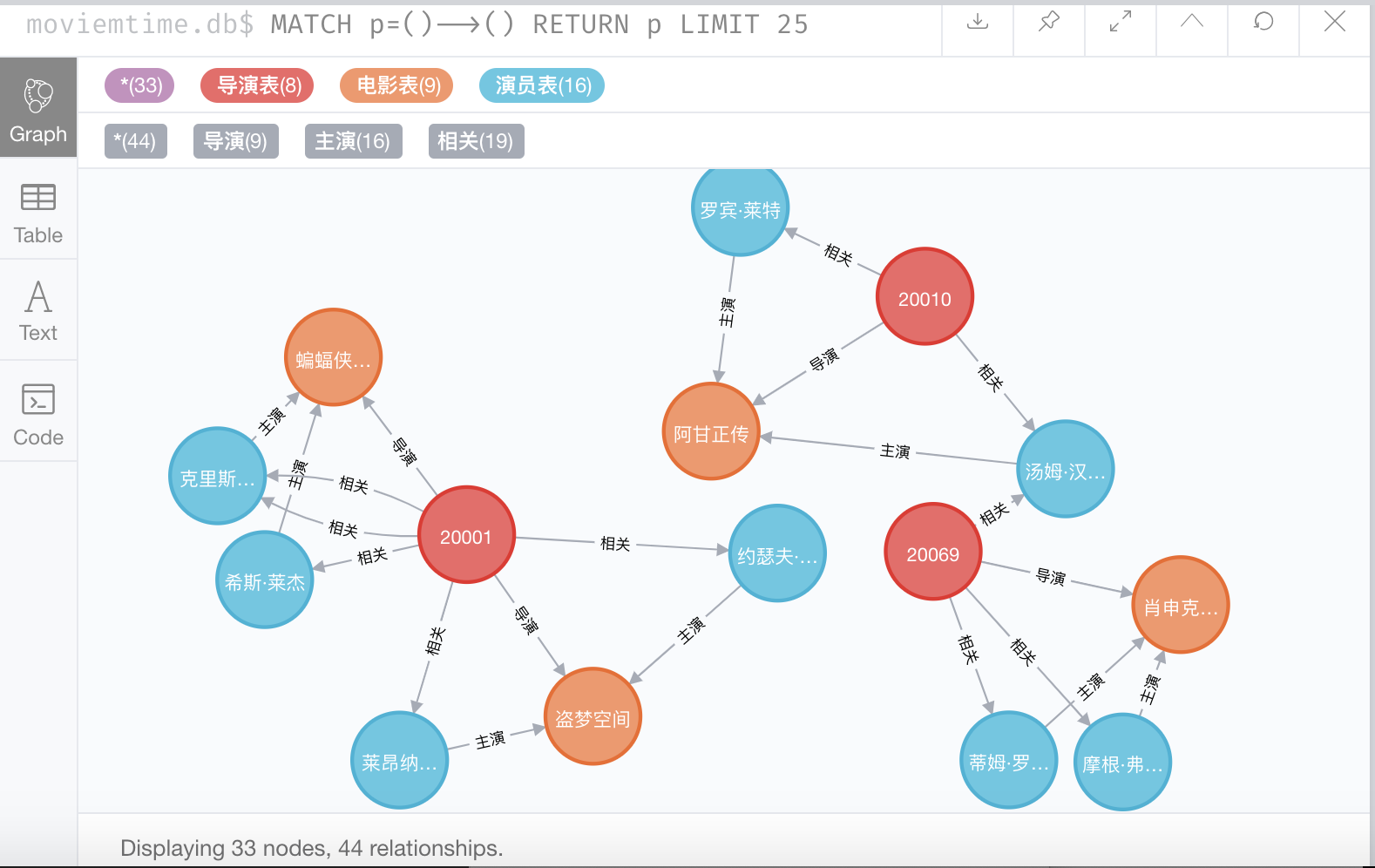
数据查询可视化
查询可视化基于Bottle框架的Web服务。
参考:GitHub: 可视化
效果如下图: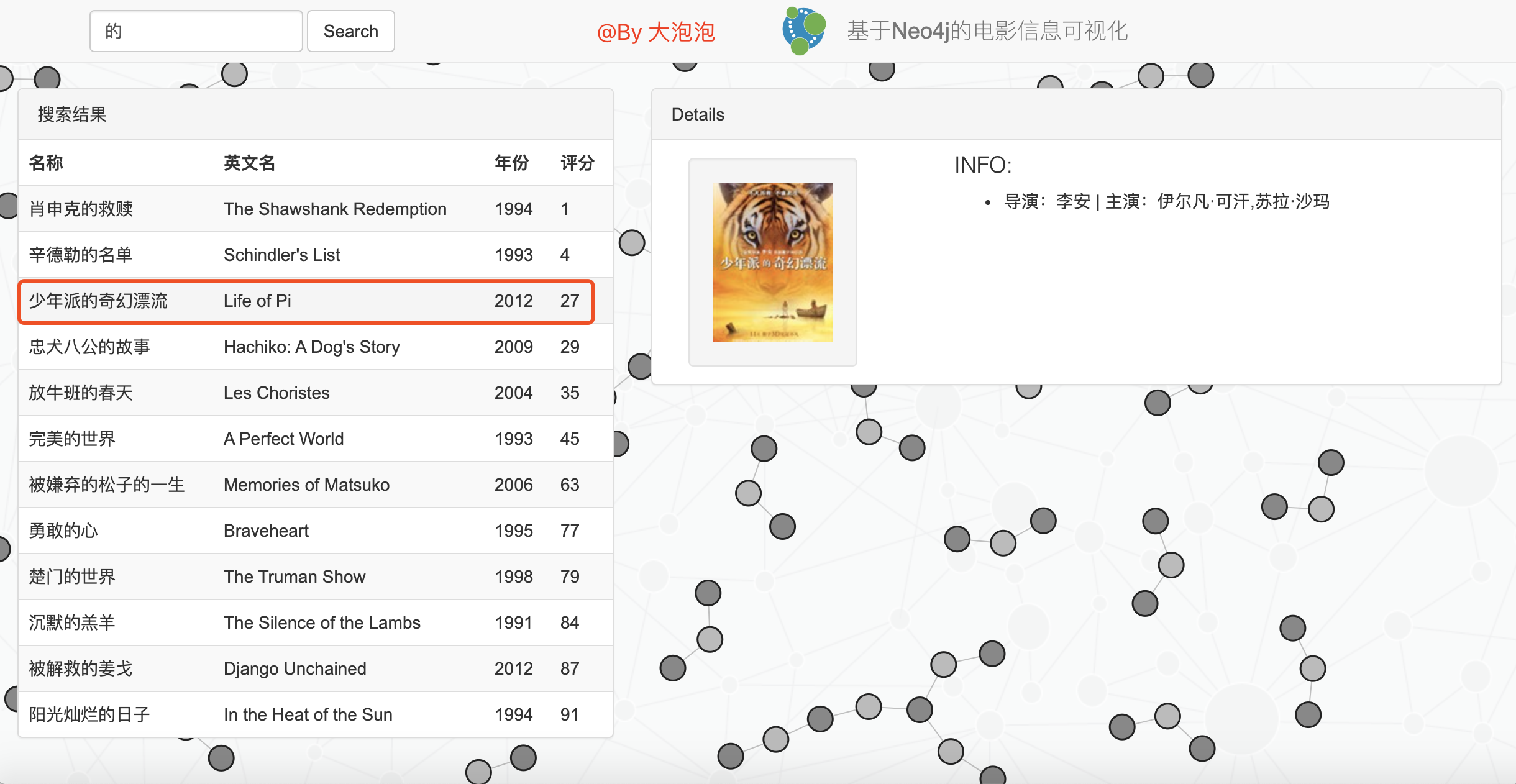
源码地址

